

Er du på udkig efter en videnskabelig artikel? Vil du gerne vide, hvordan du læser og forstår artiklen, så tjek her.
Der bliver sagt usædvanligt meget om træning og ernæring. Vi forsøger at formidle tingene, så de er til at forstå, men vi forsøger også at finde opbakning i videnskaben. Her kan du læse lidt om, hvordan vi prøver at finde viden i videnskabelige artikler og fortolker dem.
Der er ikke så meget tilgængelig viden om at læse og forstå en videnskabelig artikel og vurderinger af forskningsartikler.

Hvordan finder vi videnskabelige artikler?
Hvis et emne interesserer os, laver vi en søgning på fx pubmed.org efter emnet. Vi bruger gerne lidt forskellige søgninger og synonymer. Hvis du er forsker, så skal du kunne dokumentere, hvordan du har lavet søgningen.
Jeg læser naturligvis titlen og abstractet for at se om artiklen ser spændende ud. Hvis den gør det, så går jeg i gang med at vurdere, hvilke resultater studiet giv - og hvor solidt studiet er opbygget.
Der er virkelig meget viden om træning. Noget er der videnskabeligt belæg på, mens andre ikke helt er blevet undersøgt. Hvis du gerne vil være klogere, så kan det være interessant at dykke ned i de videnskabelige artikler.
Få adgang til de videnskabelige artikler
Desværre er der rigtig mange artikler, som man ikke umiddelbart har adgang til. Egentlig synes jeg videnskabelige artikler burde være lette at få fat på. I Danmark burde man med et Bibliotekslogin kunne læse i det mindste alle de store tidskrifter online.
Det er desværre ikke tilfældet i øjeblikket. Artiklerne er naturligvis beskyttet af copyright fra forlagene og forfatterne, så der skal være en form for ordnede forhold.
Men der er også kræfter, der arbejder på at gøre artiklerne offentlige, som er lidt i den grå afdeling på internettet. Sci-Hub er startet som en reaktion på de høje priser, forlagene tager for den videnskabelige litteratur.

Sci-Hub skifter jævnligt internet-adresse, men hvis du lige skal læse en enkelt videnskabelig artikel, som du ikke kan få adgang til, så kan du prøve at Google siden.
Hvordan er en videnskabelig artikel opbygget?
En videnskabelig artikel har næsten altid denne opbygning.
- Titel.
- Abstract.
- Introduktion.
- Metode.
- Resultater.
- Diskussion.
- Konklusion.
Hvordan læser du en videnskabelig artikel?
- Titel. Det første du læser er naturligvis titlen.
- Sidste linjer i abstractet. Jeg skimmer abstractet, men fokuserer lidt mere på de sidste par linjer for at få en fornemmelse af konklusionen i artiklen.
- Konklusion. Derefter springer jeg til det allersidste afsnit i den videnskabelige artikel for at læse lidt mere uddybende om konklusionen. Afsnittet starter næsten altid med “In summary…” eller “In conclusion…”
- Abstractet. Herefter kan du læse hele abstractet lidt mere grundigt for at få et indblik i metoder og resultater.
- Hvis du stadig synes artiklen og studiet ser spændende ud, så kan du læse hele artiklen.
Hvordan vurderer vi de videnskabelige artikler?
1. Design
Har studiet et solidt design? Hvordan måles effekten af det studiet undersøger? Er der en kontrolgruppe? Er grupperne tilfældigt sammensat? Er forsøget blindet? Det mest solide design er dobbeltblindet, randomiseret forsøg med kontrolgruppe.
2. Udvælgelseskriterier
Hvordan er forsøgspersonerne udvalgt? Bliver det sandsynliggjort at forsøgsgruppen er repræsentativ for den befolkningsgruppe, forsøget gerne vil sige noget om. Er der selektionsbias?
3. Tid
Foregår studiet over så lang tid, at det er sandsynligt, at der vil komme en effekt?
4. Kausal sammenhæng?
Bliver det sandsynliggjort at effekten skyldes det undersøgte, eller kan der være andre forklaringer?
Hvilke kriterier kigger I efter, når I forsøger at tilegne jer viden?
Videnskabelige evidenshierarki

Hvad er reliabilitet og validitet?

Du kan lære lidt mere om reliabilitet og validitet i denne video. Videoen forklarer det ganske vist ud fra et samfundsvidenskabeligt perspektiv, men begreberne validtet og reliabilitet skal forstås på samme måde.

Hvad er korrelation og kausalitet
Korrelation betyder, at der er en sammenhæng mellem ændringerne i to størrelser, men det kan være helt tilfældigt.
Kausalitet betyder, at der er en årsagssammenhæng. Det betyder at en ting påvirker en anden ting.
Hvis ikke man kan skelne mellem korrelation og kausalitet, kan man hurtigt få fejltolket en statistik:
I lang tid troede man, at sukker var direkte skyld i overvægt, da der indtil for ca. 20 år siden var en stærk korrelation mellem sukkerindtaget og forekomsten af overvægt.
US added sugar intake vs. obesity prevalence. Sugar intake has decreased more than 15% since 1999. pic.twitter.com/udhP5ubrR6
— Stephan Guyenet, PhD (@whsource) November 25, 2015
Man skal virkelig være varsom med at fortolke en korrelation som kausalitet. Tyler Vigen har lavet en side, han kalder spurious correlations.
Her er et par humoristiske eksempler på korrelationer, som næppe er kausale årsagssammenhænge.

Eller at risikoen for at blive viklet ind i sit lagen og dø og salget af ost:
Endelig en af de helt berømte eksempler på korrelationer er korrelationen mellem druknede og film med Nicolas Cage:
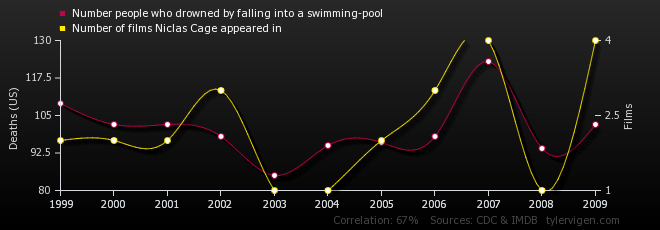
Korrelation bliver ofte forvekslet med kausalitet i medierne og i fitnessmiljøet. Når man laver fejlfortolkninger, så kan det ende med at specifikke næringsstoffer eller fødevarer bliver gjort til uretmæssig syndebuk - tag bare et kig på sukker, kulhydrater og mælkeprodukter.
Men det gælder også årsagssammenhænge i forhold til folks vægt og sindstilstand.
Selvom to datasæt og statistikker følges af, så betyder det ikke nødvendigvis at den ene ting forårsager den anden del.
Hvad er sammenhængen mellem korrelationskvotienten (r) og r2?
- R
- R er korrelationskvotienten mellem fx x og y, og den ligger mellem -1 og 1. Hvis x og y er perfekt korreleret vil den ligge på enten 1 eller -1. Hvis der ikke er nogen sammenhæng mellem x og y vil den ligge på 0.
Korrelationskvotienten giver kun mening for en simpel linær model. Hvis der er flere uafhængige variable, så kan man bruge R2.
- R2
- R2 kaldees også forklaringsgraden eller determinationskoefficientet. R2 er ganske enkelt R ganget med sig selv. R2 kan være mellem 0 og 1. Når den er tættere på 1, så er der en højere korrelation end når den nærmer sig 0.
R2 er altså mere brugbar end R, da den også kan bruges til multivariate modeller.
Du skal imidlertid være varsom med at overfortolke R2. R2-værdien må aldrig stå alene. Den skal stå sammen med fx en visualisering af data.
Der findes ingen meningsfulde globale kriterier for acceptable R2-værdier på tværs af fagområder, og man skal være meget opmærksom på ikke at misfortolke høje R2-værdier som kausalitet.
- σ
- Spredningen eller residualspredningen kan være med til at kvalificere sammenhængen. **Spredningen udtrykker den gennemsnitlige lodrette afstand til datapunkterne fra modellinjen.





{kind=link}
{kind=link}
Kommentarer